Antoine RICHERMOZ & Fabrice NEYRET - Maverick team, LJK, at INRIA-Montbonnot (Grenoble)
GPU
shaders perform an incredible amount of computations per second,
allowing more and more complex effects in games. Still, the texture
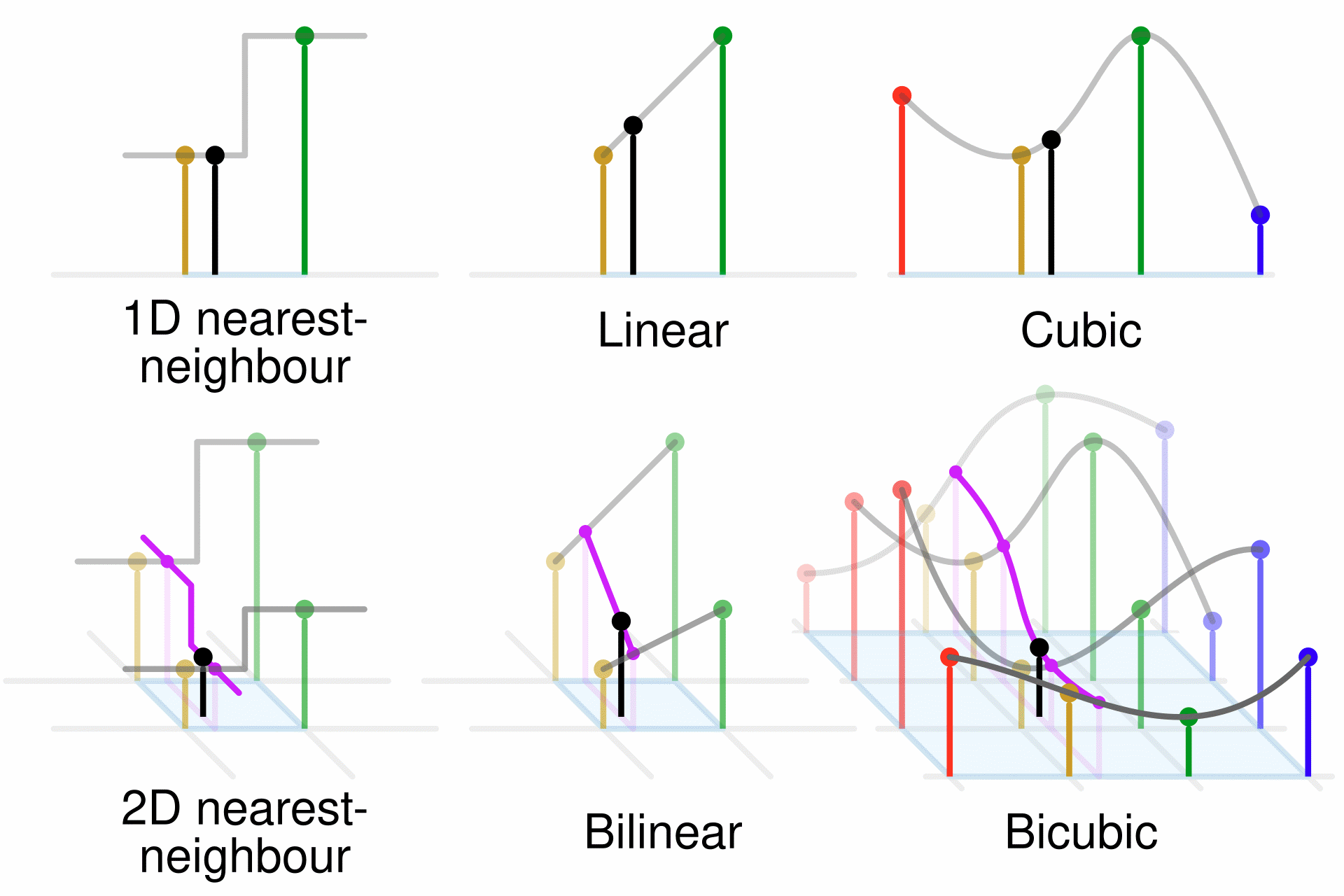
unit hides a lot of even more intensive computations it does for us:
the texture interpolation, in 2D for surface textures or in 3D for
volumes. Alas there are some cases where we can no longer rely on it:
cubic interpolation, unusual texture formats (e.g. made of tiles),
unusual blending modes (e.g. alpha-premultiply), textures of more
than 4 channels (e.g. spectrums).
Doing instead all these computations manually in the fragment shader
would be tedious and very costly, especially in 3D. But nowadays GPUs
have another powerful unit: the Tensor
Core,
and it is possible to call them from the shaders
→ Could we
divert it to do the job for us ?
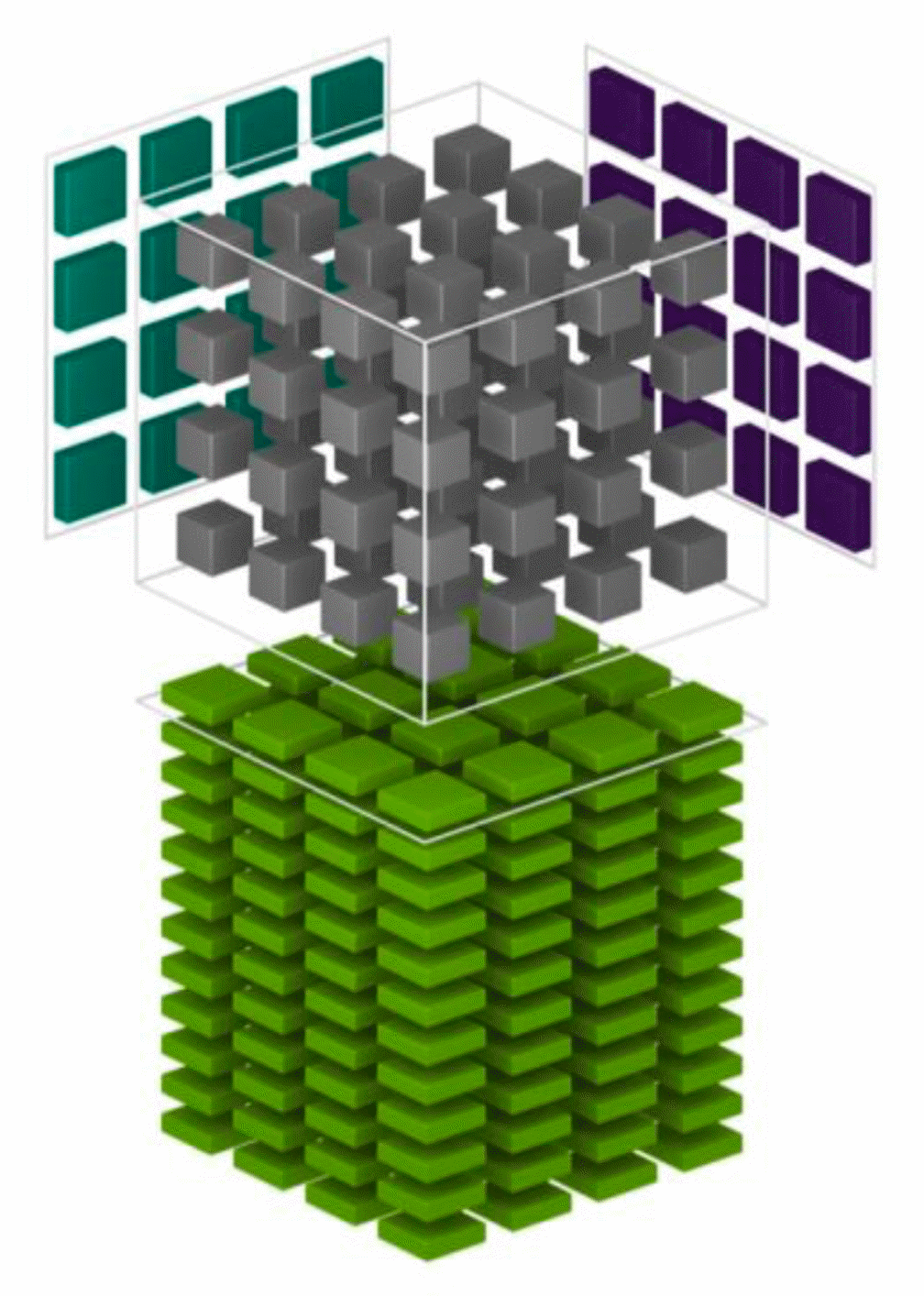
Tensor
Cores, built to accelerate deep-learning computations, are basically
engines dedicated to matrix multiply and accumulation. We can express
texture interpolation as a sum of texture value at corners times the
respective interpolation coefficient (for 2D bilinear as well as for
3D and
for
tricubic),
for the N channels of a texture buffer. Even adding an extra task
such as volume ray-marching and accumulation of a few steps would
still fit this scheme. So, the purpose of this internship subject is
to decompose the texture interpolation task as the preparation of the
coefficients in the fragment shader and the dialog with the Tensor
Core to complete the calculation. First with basic 2D bilinear color
texture interpolation,
then 2D bicubic, 3D trilinear, and as far as the experimental fate
allows – knowing that the expected gain is larger for larger
footprints.
Sadly, as often with the GPU there are
implementation constraints such as fix
set of possible sizes (strangely API-dependent, e.g. 16×8×16
and 16×8×8
in Vulkan) which not conveniently fit our data size. Padding with 0
is always possible, but it’s wasting resources, so we should find
more creative ways – knowing for instance that there exists a
“sparse
matrix” feature available in some APIs. Also, being exploring
at
the fringe of advanced and rarely explored yet ways of tickling the
GPU, we sometime bump into undocumented feature or performance
limitations: this can be pretty close to lab experiment. But sometime
we do unveil powerful secret valleys of new ways to smartly use the
GPU. In all cases, we obtain a better understanding of how the GPU
behaves at undocumented levels.
Cf links in the description.
C/C++.
Ideally Vulkan, CUDA, GLSL shading language or equivalent would be a plus.